« Rambo | Main | torrenty.org »
Bad swarm behavior
By taklamakan | January 25, 2007
When using such young software as opentracker you have to find and squash bugs, this unfortunatly involves restarting the tracker and a somewhat short period of downtime. This not only creates an ICMP unreachable packet for every connection a client would have made to the tracker but also results in an effect called “bad swam behavior”.
Why is it called “bad swarm behavior”?
A swarm in zoology, to quote from Wikipedia:
The term swarm (schooling or swarming) is applied to fish, birds and insects and describes a behavior of an aggregation (school) of animals of similar size and body orientation, generally cruising in the same direction.
This somewhat applies to P2P clients too. In the terminology of P2P applications the term swarm is applied to a group of P2P and describes a behavior of an group of clients of the same P2P protocol.
So why is it bad then? Swam behavior in networks can be bad because it can result in peaks which put load on the network or network system which under normal conditions can easily handle all the clients but is totaly uncapable of handling all clients at once! Take phone-calls at new year, its midnight and everybody calls his friends and family to congratulate on the new year. This results, at least the last years in Germany, in a total breakdown of the GSM telephone system in the countries of the particular timezone with calls not going through and SMS messages being delayed. (Yes, this can be solved by increasing the capabilities of the GSM cells, maybe just for the particular date.)
So bad swarm behavior is not a problem to P2P alone. Especially in the internet it is a problem of many client-server applications which involve reconnecting to the server in a certain time interval or clients trying to be connected all the time. Jabberserver, SMTP-server and others can have the same problem after a downtime too.
How does it happen in the case of bittorrent?
In normal operation you have clients connecting to the tracker in a certain time-interval. This interval is defined via the resposonses of the tracker to the client:
d8:completei105e10:incompletei272e8:intervali1800e5:peers300:
After a connection every client should wait 1800 seconds until the next connect. So all connections distribute over this 1800 seconds window because the time a client is started is totally random.
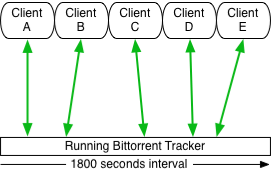
If you now stop the tracker all the client connections obviously fail. Instead of now waiting the time-interval a lot of bittorrent applications try to reconnect instantaniously to get their request completed. So they now maybe try to connect every second.
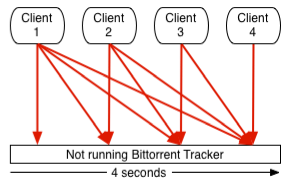
As the downtime goes on, you sort of collect most of your previously nicly distributed connections in a one-second reconnect window. In our example, after a 10 minute downtime you have collected about 30% of your clients, after 20 minutes about 60% and so on. After 30 minutes or more you have nearly all your clients trying to connect every single second. Exclude those that honor the time-interval.
What follows when you reactivate your service is clear, all those clients now connect at once! But now the well defined time-interval is active again. So you get all those clients waiting the time-interval after the first connect and then they all connect again as they are told! So they all wait 30 minutes but instead of being distributed over the 30 minutes time-window, they all connect at one point of time in this window resulting in a peak in traffic, CPU and sockets used.
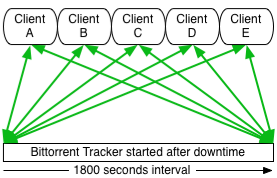
Bad swarm I say.
Of course as time evolves after the downtime, the bad swam behavior softens as clients get restartet and clocks on client computers drift. In our case it currently takes about a day and a bit after a longer downtime to completly get rid of this effect.
You can actually see this bad swarm behavior in our MRTG graph for the connections to the tracker. Green are requests and blue are actual announces. In the center you see a 30 minute downtime we had yesterday, left side is normal behavior and right is bad swarm behavior softening as time evolves:
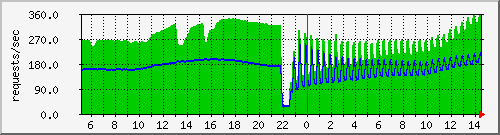 .
.
What can we do against that?
Well on the tracker side the time-interval could be modified with some random, this of course is only possible when the interval is told to the client everytime it connects but thats the case with bittorrent.
The client could also add some sort of random to the given time-interval. Both versions of adding random help somewhat but will not eliminate the problem but soften it, making it disappear faster after a downtime.
The best would be of course if all clients would wait the given time-interval independently of the services being down or not. Currently there are clients out there who ignore the interval totally trying to get new peers faster and this is really bad behavior.
Topics: tech | 1 Comment »
September 23rd, 2007 at 10:23 am
You could also put the server into a “recover” mode after the downtime where you define the maximum amount of connections to service (being 1/n) over the next n minutes; where n is your downtime and is