Bad swarm behavior
By taklamakan | January 25, 2007
When using such young software as opentracker you have to find and squash bugs, this unfortunatly involves restarting the tracker and a somewhat short period of downtime. This not only creates an ICMP unreachable packet for every connection a client would have made to the tracker but also results in an effect called “bad swam behavior”.
Why is it called “bad swarm behavior”?
A swarm in zoology, to quote from Wikipedia:
The term swarm (schooling or swarming) is applied to fish, birds and insects and describes a behavior of an aggregation (school) of animals of similar size and body orientation, generally cruising in the same direction.
This somewhat applies to P2P clients too. In the terminology of P2P applications the term swarm is applied to a group of P2P and describes a behavior of an group of clients of the same P2P protocol.
So why is it bad then? Swam behavior in networks can be bad because it can result in peaks which put load on the network or network system which under normal conditions can easily handle all the clients but is totaly uncapable of handling all clients at once! Take phone-calls at new year, its midnight and everybody calls his friends and family to congratulate on the new year. This results, at least the last years in Germany, in a total breakdown of the GSM telephone system in the countries of the particular timezone with calls not going through and SMS messages being delayed. (Yes, this can be solved by increasing the capabilities of the GSM cells, maybe just for the particular date.)
So bad swarm behavior is not a problem to P2P alone. Especially in the internet it is a problem of many client-server applications which involve reconnecting to the server in a certain time interval or clients trying to be connected all the time. Jabberserver, SMTP-server and others can have the same problem after a downtime too.
How does it happen in the case of bittorrent?
In normal operation you have clients connecting to the tracker in a certain time-interval. This interval is defined via the resposonses of the tracker to the client:
d8:completei105e10:incompletei272e8:intervali1800e5:peers300:
After a connection every client should wait 1800 seconds until the next connect. So all connections distribute over this 1800 seconds window because the time a client is started is totally random.
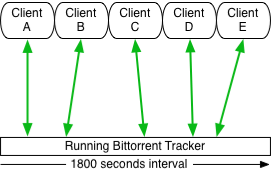
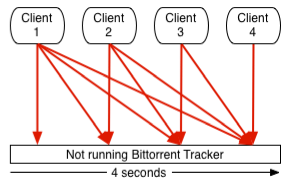
If you now stop the tracker all the client connections obviously fail. Instead of now waiting the time-interval a lot of bittorrent applications try to reconnect instantaniously to get their request completed. So they now maybe try to connect every second.
As the downtime goes on, you sort of collect most of your previously nicly distributed connections in a one-second reconnect window. In our example, after a 10 minute downtime you have collected about 30% of your clients, after 20 minutes about 60% and so on. After 30 minutes or more you have nearly all your clients trying to connect every single second. Exclude those that honor the time-interval.
What follows when you reactivate your service is clear, all those clients now connect at once! But now the well defined time-interval is active again. So you get all those clients waiting the time-interval after the first connect and then they all connect again as they are told! So they all wait 30 minutes but instead of being distributed over the 30 minutes time-window, they all connect at one point of time in this window resulting in a peak in traffic, CPU and sockets used.
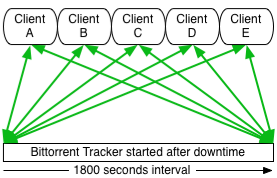
Bad swarm I say.
Of course as time evolves after the downtime, the bad swam behavior softens as clients get restartet and clocks on client computers drift. In our case it currently takes about a day and a bit after a longer downtime to completly get rid of this effect.
You can actually see this bad swarm behavior in our MRTG graph for the connections to the tracker. Green are requests and blue are actual announces. In the center you see a 30 minute downtime we had yesterday, left side is normal behavior and right is bad swarm behavior softening as time evolves:
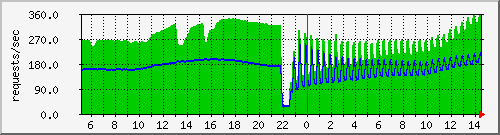 .
.
What can we do against that?
Well on the tracker side the time-interval could be modified with some random, this of course is only possible when the interval is told to the client everytime it connects but thats the case with bittorrent.
The client could also add some sort of random to the given time-interval. Both versions of adding random help somewhat but will not eliminate the problem but soften it, making it disappear faster after a downtime.
The best would be of course if all clients would wait the given time-interval independently of the services being down or not. Currently there are clients out there who ignore the interval totally trying to get new peers faster and this is really bad behavior.
Topics: tech | 1 Comment »
Rambo
By erdgeist | January 21, 2007
Surely you have seen Weird Al Yankovich making fun of Rambo movies, where dozens of villains were standing on the top of a hill, firing rounds after rounds and still being shot – one after another by our dear Al.
You might argue that a bittorrent tracker does not actually seek to kill its clients, yet the amount of fire it attracts is comparable and I always wanted to refer to “UHF” in a blog posting.
When you have to handle that many requests per seconds (I’m told, were approaching the 350 in the moment), you basically have two choices: try to figure out a complex multithreaded connection handling framework that dispatches your complex database layout or go for simplicity and try to handle request sequentially and be fast to serve them.
Before I can go into that I need to explain, what a bittorrent tracker does. In Germany there’s an institution called Mitfahrzentrale. Basically you tell them, you’re driving from one city to another at a certain date or that you would want to but lack the car. In any way, Mitfahrzentrale tells you, who also wanted to get to the same place by the same time and provides you with contact information.
With bittorrent you acquire all information you need to share a file by the .torrent file you get from bittorrent search engines. This file lists all trackers that will play Mitfahrzentrale for you plus a token to identify your ride there: a twenty bytes (160 bits) info_hash, calculated over the .torrent file.
All contact information you need to connect to another peer wanting to share the same file is its IP address and a port number its client listens on. In IPv4 thats six bytes. If you are familiar with organizing data you might by now have noticed that you just need structures to hold twenty bytes per torrent plus a pointer to a list of six byte entries for each peer.
Before I can describe, how our first important design decission evolved, you need to know about the reasons, other clients chose different designs. Bram Cohen decided to tunnel all tracker requests through HTTP (over TCP, of course) which has two draw backs. First: most requests plus its answers comfortably fit into one ethernet frame each. Having to setup a TCP connection for requests requires nine packets average instead of two, you would get when using UDP, which would even leave us with enough bandwidth for eight retries before the more reliable TCP protocol could perform better. Second: HTTP itself is an awfully complex protocol to implement. If you’re just supposed to give a simple answer to a simple question, I would argue its use is inappropriate. Considering that most firewalls let HTTP connections pass unhindered, using HTTP would be excused – if the actual data connections between peers weren’t just some binary TCP streams doomed to be filtered.
Now, when you’re using some httpd to handle the protocol for you, anyway – why bother doing the rest as a C or C++ language CGI? A typical coders reflex is to write a php-script using mysql as data backend. You learned in computer science course, that using a data base to store your data is the way to go. Right? The framework will do all the threading and forking for you, your data base ensures an appropriate locking.
Well, we thought different.
Using a kick-ass all-features-on data base? Constructing complex SQL-queries to select six byte structures from lists accessed by twenty byte indexes, that already come pre-hashed? Having a data/metadata ratio of 1:10000? Doing local data base connections, that involves setting up unix sockets again to blow up a twenty bytes request and its 50*6 bytes answer up to several kbytes overhead. No way!
All techniques to efficiently store that little data (were talking about eight MBs for 100,000 info_hashes and six MBs for 1,000,000 peers here) were around for fourty years. As already mentioned, you can use info_hash’s first bytes to address buckets, since they are already hashed. So you can easily keep sorted lists you may do binary searches in. With some minor abstractions you can sort your peers into pools you can chose to release after bittorrents peer time out.
All left to do was to find a framework to handle HTTP. Fortunally I’ve been following libowfat‘s development for a while. It is a highly scalable multi platform framework modelled after Prof. Daniel J. Bernsteins fascinating low level abstraction library, but exploiting most IO acceleration techniques like kqueue and poll. Felix von Leitner added an example httpd application that became basis for what opentracker is today. What we do is to accept, answer and close all incoming connections as fast as possible, using static buffers. This approach easily scales up to several thousand requests per second. The only reason for not having exact numbers is us being too lazy to implement stress testing software in C and all other test suites being too slow to request more than some hundred connections per second.
You can follow opentracker‘s development here.
Topics: coding | Comments Off
How it all started
By supergrobi | January 21, 2007
So how does it happen that you suddenly own a tracker on wich thousands of clients fire requests like there is no tomorrow?
Of course, we started with a small tracker (two years ago with the original python code) on a dyndns managed homerouter. It all went well, some friends used it for fast sharing things with other friends. Somehow the news got around and it handled more and more requests through the 128kbit/s uplink connection, so we had to change the provider – with a 1024kbit/s uplink it handled alot more. But when it reached ca. 90req/sec we decided it is too much for the uplink again (hey, we do occasionally also needs some bandwidth for downloading FreeBSD ISOs!). Dyndns decided to cut us off anyway for violating their policy (no service which has to do anything with filesharing).
So it was time to move the tracker to another machine with more bandwidth. There it served 160 req/sec right from the beginning. But it was still the old pythontracker source from Bram Cohen and the machine wasn’t that fast – only a 650MHz PIII. Adding a second CPU helped somewhat but the pythontracker is not threaded, so the only benefit was that the tracker could consume one complete CPU and the second CPU was free for other services on the system. We pushed about 1Mbit/s both ways back then. In December we decided to throw money at the problem and bought a new server. The fast machine handled the tracker well, but there were too much failed connections and it still used about 20-25% of one 2.4GHz Core of a Core2Duo CPU. So we decided to write our own tracker. A friend of ours took the job to do it. After some testing, debugging and drawbacks the tracker was finally ready to replace the pythoncode.
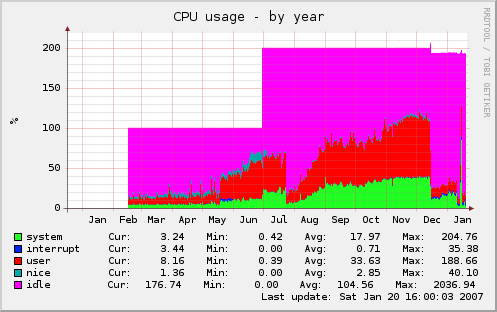
We started the new opentracker and thought it wasn’t working. Where the pythoncode needed ca. 20-25% cpu the new opentracker needed 0,00%. But we checked the requests and it really worked. I don’t give any details here because I think there will be an extra blogentry for that. It is now running since ten days. the opentracker now serves ca. 380 req/sec on ca. 10000 torrents at peaktimes. It has alot fewer failed connections now with the faster software and already pushes 2Mbit/s in and outgoing.
To really get this thing flying we will try to put it on some torrentsites upload pages.
Now you think maybe what is so exciting about running a piece of software on a piece of hardware? The problems are just begin to start. “Das Internet ist keine Blümchenwiese” (The internet is not a meadow gay with flowers ![]() )
)
There are nasty TCP/IP stacks and clients out there. Then there are ISPs who seems to not like bittorrent and alot of users which don’t behave very nice to our TCP/IP stack. We will report on that later.
Keep On Rocking In A Free World!
supergrobi
Topics: history | Comments Off
Opening Ceremony
By taklamakan | January 21, 2007
Hi and welcome to this blog about our open bittorrent tracker at http://denis.stalker.h3q.com:6969/.
Why we say its an open bittorrent tracker? Because it is, everyone can announce a torrent via http://denis.stalker.h3q.com:6969/announce without registration.
We don’t know what data is shared by using our tracker, we don’t want to know and we certainly don’t care. But because of the copyright laws in some countries, mostly they call themself liberal democracies, we have to say that content you don’t own shouldn’t be shared by using our tracker and we have to react and delete and block the torrent if the copyright owner contacts us.
To quote from our About & Abuse site:
We believe: BitTorrent trackers are like Internet Exchanges, a place were data is freely exchanged between peers in a neutral way.
We don’t know what data is exchanged, we only know hashes of data and are not responsible for what data is hashed, only peers are. We also don’t provide torrent files for download. We don’t log peers, so asking us to give out peer addresses is useless because we don’t know and we are forbidden by german law (§ 6 Abs. 1 TDDSG) to log such data.
If you think data of yours is shared by hashes we manage on this tracker and shouldn’t, please feel free to contact our abuse address with some kind of proof that the hash represents data you legally own.
abuse contact: abuse (at) denis.stalker.h3q.com
In this blog we will try to write about our work with the bittorrent tracker and the problems we face and the solutions we find while running it.
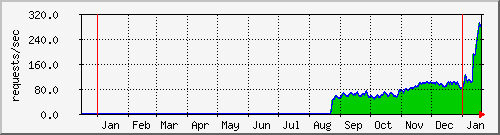
We currently serve about 10000 torrents constantly growing. The tracker serves about 300req/sec.
Topics: free speech | Comments Off
Next Entries »